Font Convert Tool
Font Convert Tool 是一款字体转换工具。它首先从多个来源获取待转换字符的 Unicode,这些来源包括标准代码页、自定义 Unicode 码表、补充码表( .txt 文件 )和自定义 .cst 文件。
随后,工具根据这些 Unicode 码,从字体文件(如 .ttf、.ttc)中提取对应字符的矢量数据。接着,它将矢量数据转换为点阵位图,最终生成 .bin 格式的输出文件。这一过程实现了从字符选择到点阵位图生成的完整转换流程。
文件准备
Font Convert Tool 需要的文件如图所示:
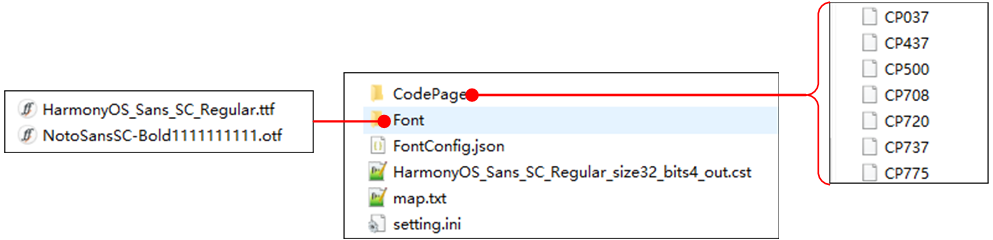
Font Convert Tool 输入文件
Codepage-
标准代码页,存放在
CodePage文件夹下,常用的有 CP936(中文)、CP20127(ASCII)、CP1252(西欧语言在 Windows 的默认编码)等。
-
map.txt文件 -
Font Tool 自定义 补充 Unicode 代码页,用于填写不包含在 Codepage 中,但是想被转换的 Unicode 字符,以 0x开头的16进制数,如下图所示:
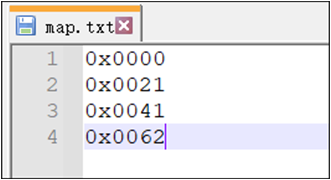
map 文件示例
-
-
cst文件 -
Font Tool 自定义 Unicode 代码页,用于存放经 Font Tool 转换的 Codepage、map.txt、customerVals(FontConfig.json 中配置) 等代码页的合集。
-
-
.ttf、.ttc等字体文件 -
存放在
Font文件夹下。
-
FontConfig.json-
Font Convert Tool 配置文件,用于配置转换参数,参数介绍如下:
JSON 文件说明 参数名称
说明
codePages
Codepage路径,多个Codepage以,进行分隔cstPaths
Unicode 代码页文件路径,多个
cst文件以,进行分隔mappingPaths
补充 Unicode 代码页,多个
map.txt文件以,进行分隔customerVals
用户自定义的连续的 Unicode 字符,多组以
,进行分隔firstVal
customerVals 的起始 Unicode,以
0x开始的 16 进制数range
customerVals 字符的个数,以
0x开始的 16 进制数fontSet
配置待转换的字体相关设置
bold
转换后的字符是否加粗
true:加粗
false:不加粗
italic
转换后的字符是否倾斜
true:倾斜
false:不倾斜
scanMode
转换后字符数据的保存方式
H:字体按行进行保存
V:字体按列进行保存
fontSize
转换后字符大小
font
转换使用的字体文件
renderMode
转换后字符位图中一个像素使用几 bit 来表示,有效值为 1、2、4、8
indexMethod
转换后输出 bin 文件重索引区的索引方式
0:地址索引
1:偏移索引
crop
是否只保存数据有效位
0:保留所有数据
1:只保留有效数据
备注
codePages、cstPaths、customerVals、mappingPaths 中填写的是待转换的 Unicode 码,可能会有重复,最终是取并集。
cstPaths、mappingPaths 需要带扩展名,codePages 不要带扩展名。
crop 模式目前只地址索引(indexmethod = 0)时生效。
setting.ini-
Font Convert Tool 定制化配置文件,参数介绍如下:
设置说明 参数名称
说明
TransformAlgrithm
转换调整算法,目前支持 gamma 变换
TransformAlgrithm 为空时不进行变换
gamma
gamma 变换的值
该值 > 1 时,会提升亮度
该值 < 1时,会降低亮度
该值 = 1 时,不进行 gamma 变换
rotate
是否对字符进行旋转
0:不旋转
1:顺时针旋转 90°
2:逆时针旋转 90°
3:旋转180°
运行流程
Font Convert Tool 运行流程如下图所示:
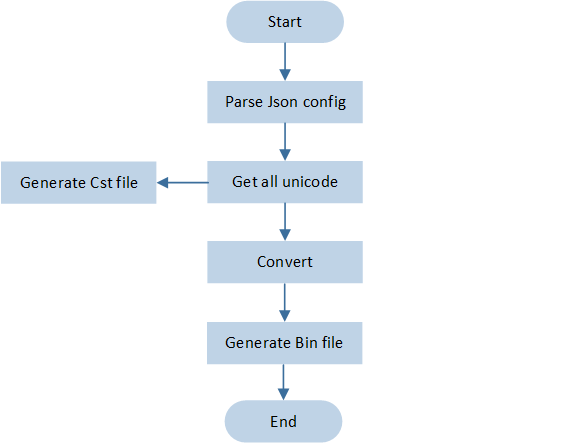
Font Convert Tool 运行流程
备注
转换命令:fontDictionary.exe [FontConfig.json路径]
输出文件
执行转换命令后,会在 Tool 文件夹下生成两个文件:*_font.bin、*_out.cst
*_font.bin
*_font.bin 是转换后的字符位图文件,此文件会烧录进 flash 中。
font.bin 结构如下所示:Header + 索引区 + 字符位图数据区
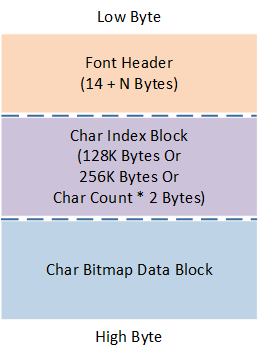
Font Bin 结构
Font Header
Font Header的结构如下图所示:
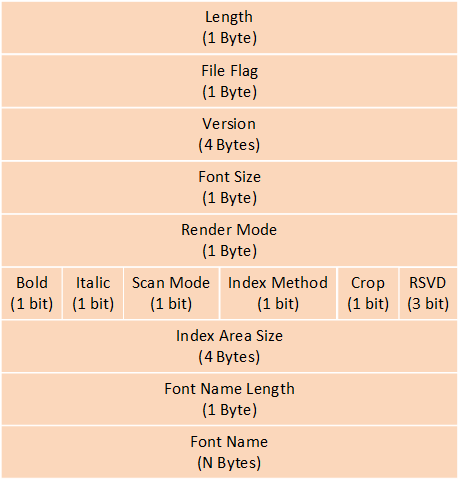
Font Header 结构
Font Header 的说明如下表所示:
参数名称 |
说明 |
|---|---|
Length |
Font Header 的长度 |
File Flag |
当前 1 表示是字体数据文件 |
Version |
版本号 |
Font Size |
字号 |
Render Mode |
转换后字符位图中一个像素使用几 bit 来表示,有效值为 1、2、4、8 |
Bold |
转换后的字符是否加粗 0:不加粗 1:加粗 |
Italic |
转换后的字符是否倾斜 0:不倾斜 1:倾斜 |
Scan Mode |
转换后字符数据的保存方式 0:字体按行进行保存 1:字体按列进行保存 |
Index Method |
转换后输出 0:地址索引 1:偏移索引 |
Font Name Length |
字体名称所占字节数 |
Font Name |
字体名称 |
索引区结构
索引区结构如下图所示:
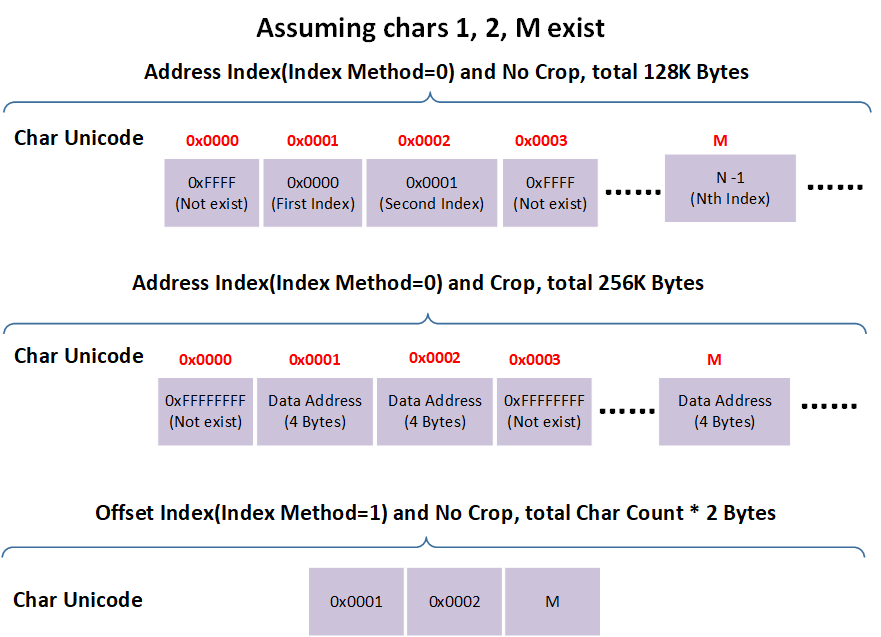
索引区结构
以索引区为 Index Buffer 为例:
-
地址索引
该索引存储所有字符的地址信息,未包含在转换范围内的字符设置为 0xFFFF(crop = 0)或者 0xFFFFFFFF(crop = 1),通过字符 Unicode 值在索引表中查询对应数据可以得到该 Unicode 对应的字符数据地址。
-
crop = 0
每个字符用 2 Bytes 存储在数据区的 Index,索引区大小为 \((0xFFFF + 1) * 2 = 128 KB\), 对于 Unicode 为 n 的字符,对应的数据地址为 \(Index Buffer[n*2] * (⌈fontSize / 8 ⌉ * fontSize * renderMode+4)\),参考 数据区结构 。
-
crop = 1
每个字符用 4 Bytes 存储在数据区的地址,索引区大小为 \((0xFFFF + 1) * 4 =256 KB\),对于 Unicode 为 n 的字符,对应的数据地址为 Index Buffer[n*4]。
-
-
偏移索引(暂时不支持 crop)
假设本次转换字符数为 m,索引区大小为:\(m * 2\) Bytes,索引区中内容为按转换顺序写入的本次转换的字符对应的 Unicode 码。对于 Unicode 为 n 的字符,首先遍历索引区,查找是否包含该字符,若该字符位于索引区的第 k Byte,则该字符的数据地址在 \(k / 2 * (⌈fontSize / 8 ⌉ * fontSize * renderMode + 4)\),参考 数据区结构 。
数据区结构
字符位图数据区,按本次转换包含的 Unicode 码对应的字符顺序保存所有字符的位图数据信息,每个保存的字符数据包含 4 字节位置信息和字符点阵数据部分,点阵数据部分大小由字体设置决定,并且会对齐到 8 bit:\(Bytes = ⌈fontSize /8⌉* fontSize * renderMode\)。
备注
例:fontSize = 12,renderMode = 4 时,字符点阵数据大小为 \(2 * 12 * 4 = 96 Bytes\),单个字符总数据大小为 \(4 + 96 = 100 Bytes\)。
*_out.cst
包含本次转换中所有用到的字符对应的 Unicode 码(此文件可以作为转换的输入,例如下次转换的时候,只需要在上次转换的基础上增加一些特殊字符时,则可以在 FontConfig.json 文件中的 cstPaths 中填入此 cst 文件,然后在 customerVals 或者 mappingPaths 中填入需要补充的字符对应的 Unicode 码,即可快速配置转换范围)。