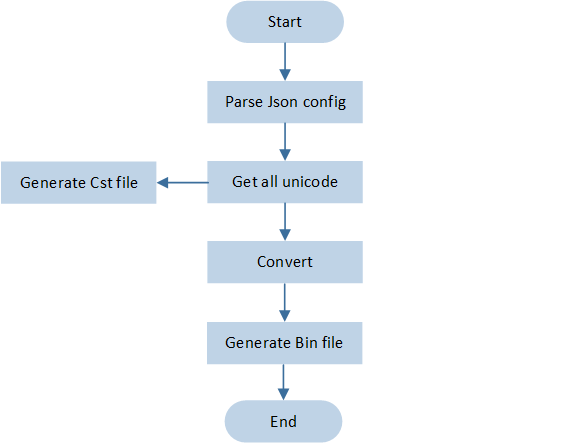
Font Convert Tool is a font conversion utility. It first retrieves the Unicode of characters to be converted from multiple sources, including standard code pages, custom Unicode code tables, supplementary code tables (.txt files), and custom .cst files.
The tool then extracts the vector data of corresponding characters from font files (e.g., .ttf, .ttc) based on these Unicode codes. Next, it converts the vector data into bitmap images and generates output files in .bin format. This process accomplishes a complete workflow from character selection to bitmap generation.
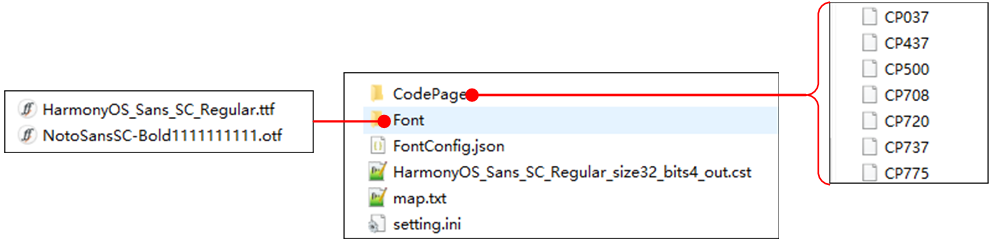
Standard codepages stored in the CodePage folder, commonly used files include CP936 for Chinese, CP20127 for ASCII, CP1252 for Western European languages on Windows, etc.
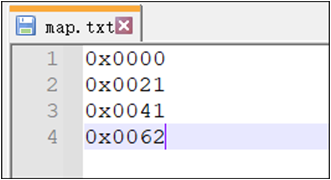
map.txt File
A Font Tool custom supplementary Unicode codepage for specifying Unicode characters not included in the Codepage but intended for conversion, represented as hexadecimal numbers starting with 0x, as shown in the figure below:
A Font Tool custom Unicode codepage that stores a collection of converted Codepage, map.txt, customerVals (configured in FontConfig.json), and other codepages.
*.ttf, *.ttc Files
Font files stored in the Font folder.
FontConfig.json
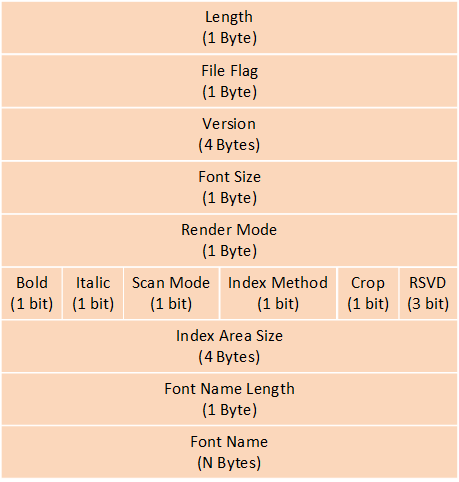
A configuration file for the Font Convert Tool to set conversion parameters, detailed as follows:
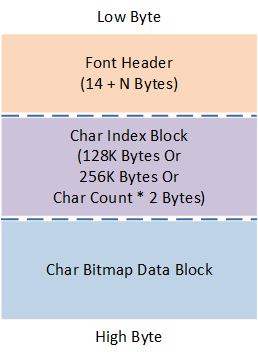
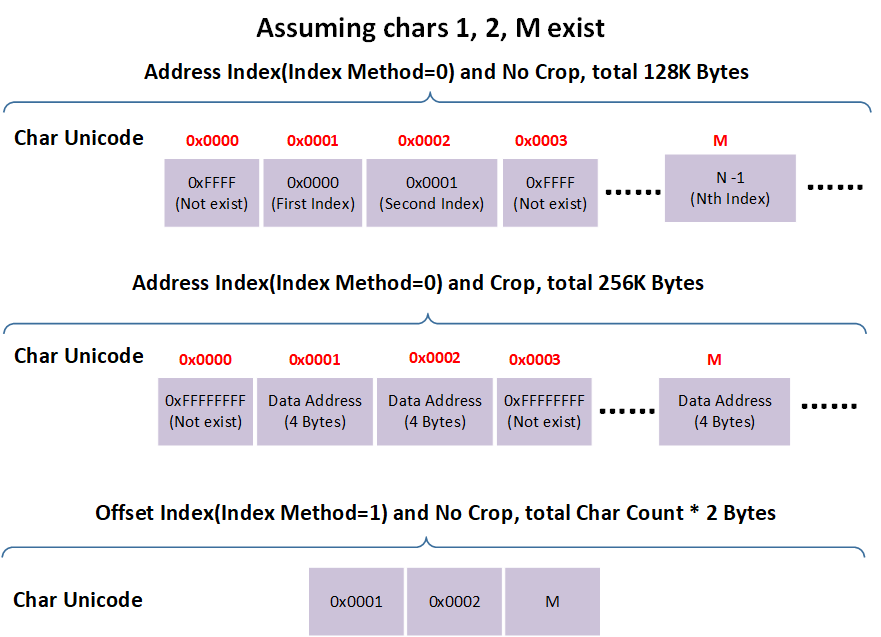
This indexing stores address information for all characters. Characters not included in the conversion range are set to 0xFFFF (crop = 0) or 0xFFFFFFFF (crop = 1). The address for the Unicode character can be found by looking up the index table with the Unicode value.
crop = 0
Each character occupies 2 Bytes in the data block's Index, with the index block size as \((0xFFFF + 1) * 2 = 128 KB\). For a character with Unicode n, the data address is \(Index Buffer[n*2] * (⌈fontSize / 8 ⌉ * fontSize * renderMode + 4)\), as referenced in the Data Block Structure.
crop = 1
Each character occupies 4 Bytes in the data block's address, with the index block size as \((0xFFFF + 1) * 4 = 256 KB\). For a character with Unicode n, the data address is Index Buffer[n*4].
Offset Indexing (currently does not support crop)
Assuming the number of characters to be converted is m , the size of the index area would be \(m * 2\) Bytes. The content of the index area consists of the Unicode codes of the characters to be converted, listed in order. For a character with Unicode n, first traverse the index area to check if it is contained. If the character is located at the k-th Byte of the index area, then the data address of the character is \(k / 2 * (⌈fontSize / 8 ⌉ * fontSize * renderMode + 4)\). Refer to the Data Block Structure.
The character bitmap data block saves all character bitmap information in the order of Unicode codes included in this conversion. Each saved character's data includes a 4-byte location header and a bitmap data part which is aligned to 8 bits, determined by font settings: \(bytes = ⌈fontSize / 8⌉ * fontSize * renderMode\).
Note
Example: If fontSize = 12 and renderMode = 4, the character's bitmap data size is \(2 * 12 * 4 = 96 Bytes\), with a total data size of \(4 + 96 = 100 Bytes\) per character.
This file includes all Unicode codes used in this conversion and can serve as an input for future conversions. For instance, in subsequent conversions when only additional special characters are needed, the .cst file from a previous conversion can be referenced by including it in the cstPaths field of the FontConfig.json file, and any additional character Unicode codes can be included in customerVals or mappingPaths for quick configuration of the conversion range.