Font Porting
This chapter will analyze the font library code segment and explain how to replace HoneyGUI's native font library with a custom one provided by the developer, or how to add customized features.
Dot Matrix Font Library Porting
Glyph Loading
Text Encoding Conversion
In the file font_mem.c, within the function gui_font_get_dot_info(),
process_content_by_charset() parses the text content of the text widget and saves it as Unicode (UTF-32) in unicode_buf.
The number of Unicode characters is returned in unicode_len.
uint32_t *unicode_buf = NULL;
uint16_t unicode_len = 0;
unicode_len = process_content_by_charset(text->charset, text->content, text->len, &unicode_buf);
if (unicode_len == 0)
{
gui_log("Warning! After process, unicode len of text: %s is 0!\n", text->base.name);
text->font_len = 0;
return;
}
For the specific implementation of process_content_by_charset(), please refer to draw_font.c.
Note
The parsing process supports UTF-8, UTF-16, and UTF-32.
Subsequently, Unicode information in unicode_buf will be used to index text data from the font library.
Text encoding conversion for minor languages, such as Arabic character concatenation and other calculations involving Unicode,
can be performed either before or after the encoding conversion. If the conversion is done later, unicode_len must be updated accordingly.
Note
The unit of unicode_len is bytes, not the number of characters.
Font Library Indexing
In the file font_mem.c, within the function gui_font_get_dot_info(),
the Unicode value is parsed and then used to index glyph information from the font library designated by the text widget.
Since the font library tool has the crop attribute and two indexing modes,
different parsing code is used to find text data and dot matrix data in the font library file using the Unicode value.
The purpose of the font library parsing code is to populate the chr structure array, which is structured as follows:
typedef struct
{
uint32_t unicode;
int16_t x;
int16_t y;
int16_t w;
int16_t h;
uint8_t char_y;
uint8_t char_w;
uint8_t char_h;
uint8_t render_mode; /**< bits-per-pixel (1/2/4/8), from source font (fills padding) */
uint8_t *dot_addr;
uint8_t *buf;
void *emoji_img;
#if ENABLE_FONT_V3_TYPO
/* V3 bearing-based fields (zero-initialized for V1 glyphs) */
int8_t bearing_x; /**< V3: horizontal bearing (pixels) */
int8_t bearing_y; /**< V3: vertical bearing from baseline to glyph top (pixels) */
uint8_t advance; /**< V3: horizontal advance width (pixels) */
#endif
} mem_char_t;
Each member has the following meanings:
Unicode: The Unicode of the dot matrix text, expressed in UTF-32LE format.x: The X-coordinate of the upper-left corner of the dot matrix text boundary, determined during layout, used to set the drawing coordinates of the text.y: The Y-coordinate of the upper-left corner of the dot matrix text boundary, determined during layout, used to set the drawing coordinates of the text.w: The data width of the character in the dot matrix data. Due to byte alignment and compression characteristics, this value is not always equal to the font size.h: The height of the dot matrix text, which is always equal to the font size, used to define the basic drawing area and for multi-line layout.char_y: The number of blank rows above the character, representing the Y-coordinate distance between the topmost pixel of the text dot matrix and the upper boundary, used to constrain the drawing area.char_w: The pixel width of the character, representing the difference in the X-coordinate between the leftmost boundary (starting point) and the rightmost pixel of the text. This value is used to constrain the drawing area during drawing and represents the text width during layout.char_h: The pixel height of the character, representing the Y-coordinate distance between the bottommost pixel of the text dot matrix and the upper boundary. The value ofchar_hminuschar_ygives the actual pixel height of the dot matrix.dot_addr: The starting address of the dot matrix data corresponding to the text.emoji_img: The pointer to the widget corresponding to the Emoji image. This value is NULL if the Emoji feature is not used.
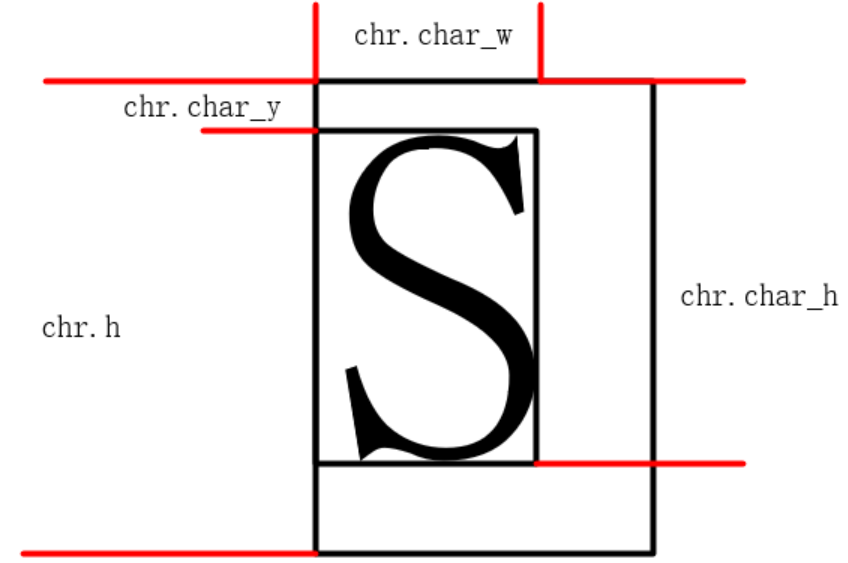
Glyph Example
During the font library indexing phase, all members of chr except for the x and y coordinates will be populated to prepare for the next step of layout.
Note
Due to differences in data storage rules under different modes, the drawing areas also vary. For example, char_y and char_h are only effective when crop=1 and index_method=0.
Since this stage involves using the Unicode to look up width information for the dot matrix text and the dot matrix data pointer, it's best to complete the Unicode-level text transformations before this step. For example, Arabic script ligatures should be handled in this stage, whereas Thai glyph fusion should be handled during the layout stage.
If you are porting using your custom font library, you can populate the chr data structures using information from your custom font library.
The default parts can be used for the subsequent layout and drawing stages.
Layout
The text widget supports various layout modes.
The specific layout functionality is located in the file font_mem.c in the function gui_font_mem_layout().
Each layout mode has a different layout logic; however, all depend on the glyph information chr and the boundary information rect provided by the text widget.
The rect struct array is structured as follows:
typedef struct gui_text_rect
{
int16_t x1;
int16_t y1;
int16_t x2;
int16_t y2;
int16_t xboundleft;
int16_t xboundright;
int16_t yboundtop;
int16_t yboundbottom;
} gui_text_rect_t;
The rect is the display range of the widget passed from the widget layer. In this structure,
x1 and x2 represent the X-coordinates of the left and right borders, respectively,
while y1 and y2 represent the Y-coordinates of the top and bottom borders, respectively.
These values are calculated internally by the widget based on its position and size at the time of creation.
From the four coordinates of rect, you can calculate rect_w (width) and rect_h (height).
There are also four bound values used by the scrolling text widget (scroll_text) to handle display boundaries.
These bound values are currently not used by the regular text widget (text).
Developers can add new layout modes as per their requirements.
By enabling the English word wrapping feature (wordwrap) via the function gui_text_wordwrap_set,
the multi-line layout will adhere to English word wrapping rules to prevent words from being split across lines.
Character Rendering
The code for rendering bitmap characters is located in the rtk_draw_unicode function in font_mem.c.
You can enable matrix operations for the text widget to support text scaling effects;
the rendering code for this feature is in rtk_draw_unicode_matrix in font_mem_matrix.c.
Additionally, you can enable a feature to convert text into an image for achieving complex effects;
this rendering code is found in gui_font_bmp2img_one_char in font_mem_img.c.
The character rendering stage does not involve any layout information; it only reads the glyph information and renders it to the screen buffer.
Each character's rendering is constrained by three boundaries: the widget's boundary, the screen's boundary, and the current character's boundary.
If developers wish to use a special font library for rendering, they need to modify the bitmap data parsing code and draw the pixels into the screen buffer.
API
Defines
-
FONT_MALLOC_PSRAM(x) gui_malloc(x)
-
FONT_FREE_PSRAM(x) gui_free(x)
-
FONT_FILE_BMP_FLAG 0x01
Functions
-
uint8_t gui_font_mem_init(uint8_t *font_bin_addr)
-
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters:
-
font_bin_addr -- Binary file address of this font type.
- Returns:
-
Font library index.
-
uint8_t gui_font_mem_init_ftl(uint8_t *font_bin_addr)
-
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters:
-
font_bin_addr -- Font file address.
- Returns:
-
Font library index.
-
uint8_t gui_font_mem_init_fs(uint8_t *font_bin_addr)
-
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters:
-
font_bin_addr -- Font file address.
- Returns:
-
Font library index.
-
uint8_t gui_font_mem_init_mem(uint8_t *font_bin_addr)
-
Initialize the character binary file and store the font and corresponding information in the font list.
- Parameters:
-
font_bin_addr -- Font file address.
- Returns:
-
Font library index.
-
uint8_t gui_font_mem_delete(uint8_t *font_bin_addr)
-
Destroy this font type in font list.
- Parameters:
-
font_bin_addr -- Font file address.
- Returns:
-
Font library index.
-
void gui_font_mem_load(gui_text_t *text, gui_text_rect_t *rect)
-
Preprocessing of bitmap fonts using internal engines.
- Parameters:
text -- Widget pointer.
rect -- Widget boundary.
-
void gui_font_mem_draw(gui_text_t *text, gui_text_rect_t *rect)
-
Drawing of bitmap fonts using internal engine.
- Parameters:
text -- Widget pointer.
rect -- Widget boundary.
-
void gui_font_mem_unload(gui_text_t *text)
-
Post-processing work for drawing bitmap fonts using internal engines.
- Parameters:
-
text -- Widget pointer.
-
void gui_font_mem_destroy(gui_text_t *text)
-
GUI_FONT_SRC_BMP text widget destroy function.
- Parameters:
-
text -- Widget pointer.
-
FONT_LIB_NODE *get_fontlib_by_size(uint16_t font_size)
-
Get the font library node by size.
- Parameters:
-
font_size -- Font size.
- Returns:
-
Font library node pointer, or NULL if not found.
-
FONT_LIB_NODE *get_fontlib_by_name(uint8_t *font_file)
-
Get the font library node by name.
- Parameters:
-
font_file -- Font file.
- Returns:
-
Font library node pointer, or NULL if not found.
-
void gui_font_mem_layout(gui_text_t *text, gui_text_rect_t *rect)
-
Text layout by mode.
Text layout by mode.
- Parameters:
text -- Widget pointer.
rect -- Widget boundary.
chr -- Glyph to position (bearing_x/y, advance must be filled)
cursor_x -- Current horizontal cursor (updated on return)
line_y -- Top Y of current line
baseline_px -- Baseline offset from line top (pixels)
letter_spacing -- Extra letter spacing
-
void gui_font_get_dot_info(gui_text_t *text)
-
Get dot information by utf-8 or utf-16.
- Parameters:
-
text -- Widget pointer.
-
int gui_font_bmp_fallback_search(uint32_t unicode, uint8_t font_size, uint8_t *skip_file, mem_char_t *out_chr, int32_t *out_line_byte)
-
Search for a glyph in all registered BMP fonts (fallback). Iterates font_lib nodes with matching font_size, ordered by priority, skipping the primary font. Only searches BMP type fonts.
Search for a glyph in all registered BMP fonts (fallback). Iterates font_lib nodes with matching font_size, ordered by priority, skipping the primary font. Only searches BMP type fonts.
Iterates font_lib nodes with matching font_size, ordered by priority, skipping the primary font.
- Parameters:
unicode -- Unicode code point to search.
font_size -- Font size to match.
skip_file -- Primary font file to skip (already searched).
out_chr -- Output character info (populated on success).
out_line_byte -- Output line byte width.
- Returns:
-
0 on success, -1 if not found in any fallback BMP font.
-
struct GUI_CHAR_HEAD
-
struct MEM_FONT_LIB
-
struct GUI_FONT_HEAD_BMP
Defines
-
ENABLE_FONT_V3_TYPO 1
Enums
Functions
-
uint16_t process_content_by_charset(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len, uint32_t **p_buf_ptr)
-
Converts content from a specified charset to Unicode code points.
- Parameters:
charset_type -- Charset type of the content.
content -- Input content to be converted.
len -- Length of the input content in bytes.
p_buf_ptr -- Pointer to the buffer that will hold the Unicode code points.
- Returns:
-
Length of the Unicode code points array.
-
uint32_t get_len_by_char_num(uint8_t *utf8, uint32_t char_num)
-
Get the len by char num object.
- Parameters:
utf8 -- UTF8 string pointer.
char_num -- Number of characters.
- Returns:
-
Length of the UTF8 string in bytes.
-
uint32_t generate_emoji_file_path_from_unicode(const uint32_t *unicode_buf, uint32_t len, char *file_path)
-
Function to generate file path based on a given Unicode sequence.
- Parameters:
unicode_buf -- Unicode buffer to generate file path from.
len -- Length of the Unicode buffer.
file_path -- Output file path buffer.
- Returns:
-
Length of the generated file path.
-
bool content_has_ap_unicode(uint32_t *unicode_buf, uint32_t len)
-
Check if the content has any Arabic or Persian Unicode characters.
- Parameters:
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns:
-
true If the content has any Arabic or Persian Unicode characters.
- Returns:
-
false If the content does not have any Arabic or Persian Unicode characters.
-
bool content_has_ap(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
-
Check if the content has any Arabic or Persian Unicode characters.
- Parameters:
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns:
-
true If the content has any Arabic or Persian Unicode characters.
- Returns:
-
false If the content does not have any Arabic or Persian Unicode characters.
-
uint32_t process_ap_unicode(uint32_t *unicode_buf, uint32_t unicode_len)
-
Process Arabic or Persian Unicode characters in the content.
- Parameters:
unicode_buf -- Unicode buffer to process.
unicode_len -- Length of the Unicode buffer.
- Returns:
-
uint32_t The length of the processed Unicode buffer.
-
bool content_has_thai_unicode(uint32_t *unicode_buf, uint32_t len)
-
Check if the content has any Thai Unicode characters.
- Parameters:
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns:
-
true If the content has any Thai Unicode characters.
- Returns:
-
false If the content does not have any Thai Unicode characters.
-
bool content_has_thai(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
-
Check if the content has any Thai Unicode characters.
- Parameters:
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns:
-
true If the content has any Thai Unicode characters.
- Returns:
-
false If the content does not have any Thai Unicode characters.
-
uint32_t get_thai_mark_char_width(mem_char_t *chr, uint32_t char_count)
-
Get the width sum of mark Thai characters.
- Parameters:
chr -- The memory character array.
char_count -- The count of characters.
- Returns:
-
uint32_t The width sum of Thai characters.
-
uint32_t process_thai_char_struct(mem_char_t *chr, uint32_t unicode_len, THAI_MARK_INFO **mark_array_out, uint32_t *mark_count_out)
-
Process Thai character struct.
- Parameters:
chr -- The memory character array.
unicode_len -- The length of the Unicode buffer.
mark_array_out -- Pointer to the array that will hold the Thai mark information.
mark_count_out -- Pointer to the variable that will hold the count of Thai marks.
- Returns:
-
uint32_t The length of the processed base Thai Unicode buffer.
-
uint32_t post_process_thai_char_struct(mem_char_t *chr, uint32_t base_count, uint32_t active_base, uint32_t mark_count, THAI_MARK_INFO *marks)
-
Post process Thai character struct.
- Parameters:
chr -- The memory character array.
base_count -- The count of base Thai characters.
mark_count -- The count of mark Thai characters.
active_base -- The count of active base Thai characters.
marks -- The Thai mark information array.
- Returns:
-
uint32_t Finally active length include base and mark.
-
bool content_has_hebrew_unicode(uint32_t *unicode_buf, uint32_t len)
-
Check if the content has any Hebrew Unicode characters.
- Parameters:
unicode_buf -- Unicode buffer to check.
len -- Length of the Unicode buffer.
- Returns:
-
true If the content has any Hebrew Unicode characters.
- Returns:
-
false If the content does not have any Hebrew Unicode characters.
-
bool content_has_hebrew(TEXT_CHARSET charset_type, uint8_t *content, uint16_t len)
-
Check if the content has any Hebrew Unicode characters.
- Parameters:
charset_type -- The charset type of the content.
content -- Input content to be checked.
len -- Length of the input content in bytes.
- Returns:
-
true If the content has any Hebrew Unicode characters.
- Returns:
-
false If the content does not have any Hebrew Unicode characters.
-
struct gui_text_rect_t
-
struct mem_char_t
-
Public Members
-
uint32_t unicode
-
int16_t x
-
int16_t y
-
int16_t w
-
int16_t h
-
uint8_t char_y
-
uint8_t char_w
-
uint8_t char_h
-
uint8_t render_mode
-
bits-per-pixel (1/2/4/8), from source font (fills padding)
-
uint8_t *dot_addr
-
uint8_t *buf
-
void *emoji_img
-
int8_t bearing_x
-
V3: horizontal bearing (pixels)
-
int8_t bearing_y
-
V3: vertical bearing from baseline to glyph top (pixels)
-
uint8_t advance
-
V3: horizontal advance width (pixels)
-
uint32_t unicode
-
struct ap_chars_map_t
-
struct THAI_MARK_INFO